The easiest technique used for mapping is known as direct mapping. The direct mapping maps every block of the main memory into only a single possible cache line. In simpler words, in the case of direct mapping, we assign every memory block to a certain line in the cache.
In this article, we will take a look at Direct Mapping according to the GATE Syllabus for CSE (Computer Science Engineering). Read ahead to learn more.
Table of Contents
- What is Direct Mapping?
- Physical Address Division
- Direct Mapped Cache
- Implementation
- Hit latency
- Important Results
What is Direct Mapping?
In the case of direct mapping, a certain block of main memory would be able to map to only a particular line of cache. Here, the line number of the cache to which any given block can map is basically given by this:
Cache line number = (The Block Address of the Main Memory ) Modulo (Total number of lines present in the cache)
Physical Address Division
The physical address, in the case of direct mapping, is divided as follows:

Division of Physical Address in Direct Mapping
Direct Mapped Cache
The direct-mapped cache would employ a technique of direct cache mapping. Here are the steps that explain the actual working of a direct-mapped cache:
After the CPU yields a memory request,
- Use the line number field of the address in order to access a particular line of a given cache.
- Then, compare the tag field of the address of the CPU with the tag of the line.
- In case the two tags match, then a cache hit would occur, and the desired word would be found in that cache.
- In case the two tags don’t match at all, then a cache miss would occur.
- Now, in the case of a cache miss, the word that we require needs to be brought from a system’s main memory.
- Then, it is stored in the cache along with the new tag that replaces the previous one.
Implementation
Here is a diagram that shows the implementation of a direct-mapped cache:
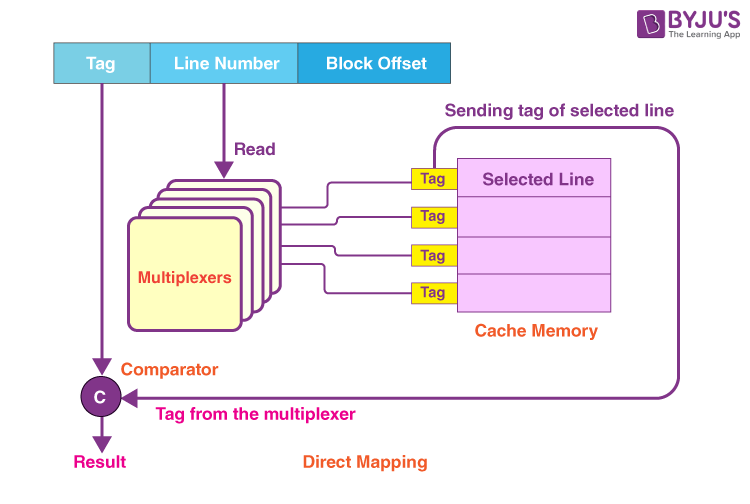
(This diagram, for simplicity, doesn’t show all the lines present in the multiplexers)
Here are the steps that are involved in this process:
Step-01
- Every multiplexer reads the given line number from the physical address generated using the select lines in parallel.
- In order to read the line number of a total of L bits, the total number of select lines that every multiplexer has should be equal to L.
Step-02
- Once the reading of the line number is done, all the multiplexers go to the line corresponding in the cache memory with the help of its parallel input lines.
- The total number of input lines every multiplexer has = The total number of lines present in the memory of the cache.
Step-03
- A multiplexer outputs a tag bit that it selects from that to the comparator with the help of its output line.
- The total number of output lines present in each multiplexer should be equal to 1.
Note:
It is very important to understand that:
- Any multiplexer would be able to output just a single bit on the line of output.
- Thus, to output a complete tag to a comparator,
The total number of multiplexers that are required = The total number of bits present in the tag
- The configuration of every multiplexer is to read the tag bit that is present at a specific location.
For Example
- The configuration of the first multiplexer is to output the tag’s first bit.
- The configuration of the second multiplexer is to output the tag’s second bit.
- The configuration of the third multiplexer is to output the tag’s third bit.
Thus,
- Every multiplexer selects the selected line’s tag bit for which it’s been configured and then outputs on the line of output.
- The complete tag is sent as a whole to the comparator to perform the comparison in parallel.
Step-04
- The comparator then compares the tag that is coming from the multiplexers along with the tag of the address that has been generated.
- Just one of the comparators is needed for the comparison, in which:
The size of the comparator = The total number of bits in a tag
- In case the two tags happen to match, a cache hit would occur, or else a cache miss would occur.
Hit latency
The total time taken to find out if the word that is required is present in the memory of the cache or not is called the hit latency.
For a direct-mapped cache,
Hit latency = Comparator latency + Multiplexer latency
Important Results
Here are a few crucial results for a direct-mapped cache:
- The block j of the main memory is capable of mapping to line number only (the number of j mod lines in cache) of the cache.
- The total number of multiplexers that are required = The total number of bits present in the tag.
- The size of every multiplexer = The total number of lines present in the cache x 1
- Total number of required comparators = 1
- The size of the comparator = The total number of bits present in the tag
- Hit latency = Comparator latency + Multiplexer latency
Keep learning and stay tuned to BYJU’S to get the latest updates on GATE Exam along with GATE Eligibility Criteria, GATE 2024, GATE Admit Card, GATE Application Form, GATE Syllabus, GATE Cutoff, GATE Previous Year Question Paper, and more.
Also Explore,
- Types of Instructions in Computer Architecture
- ALU (Arithmetic Logic Unit)
- Control Unit
- Microprogrammed Control Unit
- Instruction Formats
- Addressing Modes
- Memory Hierarchy
- Fully Associative Mapping
- Associative Mapping
- Conversion of Bases to Other Bases
- Flynn’s Classification of Computers
- SIMD
- SISD
- MIMD
- MISD
- De Morgan’s Theorems
Comments