Frequency Distribution Table – Data Collection
In our day to day life, recording information is very crucial. A piece of information or representation of facts or ideas which can be further processed is known as data. The weather forecast, maintenance of records, dates, time, and everything is related to data collection.
The collection, presentation, analysis, organization and interpretation of observations or data is known as statistics. We can make predictions about the nature of data based on the previous data using statistics. Statistics are helpful when a large amount of data is to be studied and observed.
The collected statistical data can be represented by various methods such as tables, bar graphs, pie charts, histograms, frequency polygons, etc.
In the upcoming discussion, data collection through a frequency distribution table is discussed.

What is Frequency Distribution Table in Statistics?
In statistics, a frequency distribution table is a comprehensive way of representing the organisation of raw data of a quantitative variable. This table shows how various values of a variable are distributed and their corresponding frequencies. However, we can make two frequency distribution tables:
(i) Discrete frequency distribution
(ii) Continuous frequency distribution (Grouped frequency distribution)
| Read more: |
How to Make a Frequency distribution table?
Frequency distribution tables can be made using tally marks for both discrete and continuous data values. The way of preparing discrete frequency tables and continuous frequency distribution tables are different from each other.
In this section, you will learn how to make a discrete frequency distribution table with the help of examples.
Examples
Suppose the runs scored by the 11 players of the Indian cricket team in a match are given as follows:
This type of data is in raw form and is known as raw data. The difference between the measure of highest and lowest value in a collection of data is known as the range. Here, the range is-
When the number of observations increases, this type of representation is quite hectic, and the calculations could be quite complex. As statistics is about the presentation of data in an organized form, the data representation in tabular form is more convenient.
Considering another example: In a quiz, the marks obtained by 20 students out of 30 are given as:
This data can be represented in tabular form as follows:
Table 1: Frequency Distribution Table (Ungrouped)
| Marks obtained in quiz | Number of students(Frequency) |
| 12 | 1 |
| 15 | 4 |
| 16 | 1 |
| 17 | 1 |
| 19 | 1 |
| 20 | 2 |
| 21 | 3 |
| 23 | 2 |
| 24 | 1 |
| 29 | 1 |
| 30 | 3 |
| Total | 20 |
The number of times data occurs in a data set is known as the frequency of data. In the above example, frequency is the number of students who scored various marks as tabulated. This type of tabular data collection is known as an ungrouped frequency table.
What happens if, instead of 20 students, 200 students took the same test. Would it have been easy to represent such data in the format of an ungrouped frequency distribution table? Well, obviously no. To represent a vast amount of information, the data is subdivided into groups of similar sizes known as class or class intervals, and the size of each class is known as class width or class size.
Frequency Distribution table for Grouped data
The frequency distribution table for grouped data is also known as the continuous frequency distribution table. This is also known as the grouped frequency distribution table. Here, we need to make the frequency distribution table by dividing the data values into a suitable number of classes and with the appropriate class height. Let’s understand this with the help of the solved example given below:
Question:
The heights of 50 students, measured to the nearest centimetres, have been found to be as follows:
161, 150, 154, 165, 168, 161, 154, 162, 150, 151, 162, 164, 171, 165, 158, 154, 156, 172, 160, 170, 153, 159, 161, 170, 162, 165, 166, 168, 165, 164, 154, 152, 153, 156, 158, 162, 160, 161, 173, 166, 161, 159, 162, 167, 168, 159, 158, 153, 154, 159
(i) Represent the data given above by a grouped frequency distribution table, taking the class intervals as 160 – 165, 165 – 170, etc.
(ii) What can you conclude about their heights from the table?
Solution:
(i) Let us make the grouped frequency distribution table with classes:
150 – 155, 155 – 160, 160 – 165, 165 – 170, 170 – 175
Class intervals and the corresponding frequencies are tabulated as:
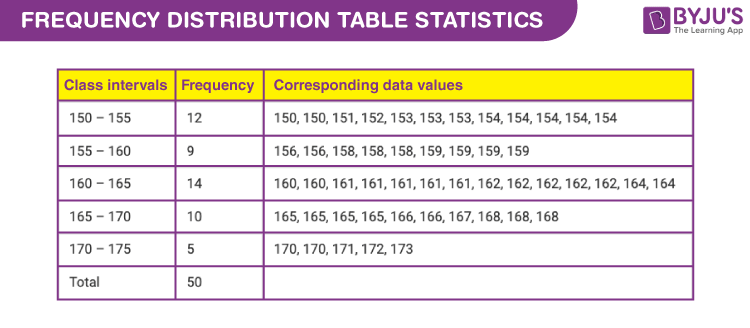
(ii) From the given data and above table, we can observe that 35 students, i.e. more than 50% of the total students, are shorter than 165 cm.
Practice Problems
- The scores (out of 100) obtained by 33 students in a mathematics test are as follows:
69, 48, 84, 58, 48, 73, 83, 48, 66, 58, 84000 66, 64, 71, 64, 66, 69, 66, 83, 66, 69, 71 81, 71, 73, 69, 66, 66, 64, 58, 64, 69, 69
Represent this data in the form of a frequency distribution. - The following are the marks (out of 100) of 60 students in mathematics.
16, 13, 5, 80, 86, 7, 51, 48, 24, 56, 70, 19, 61, 17, 16, 36, 34, 42, 34, 35, 72, 55, 75, 31, 52, 28,72, 97, 74, 45, 62, 68, 86, 35, 85, 36, 81, 75, 55, 26, 95, 31, 7, 78, 92, 62, 52, 56, 15, 63,25, 36, 54, 44, 47, 27, 72, 17, 4, 30.
Construct a grouped frequency distribution table with width 10 of each class starting from 0 – 9. - The value of π up to 50 decimal places is given below: 3.14159265358979323846264338327950288419716939937510
(i) Make a frequency distribution of the digits from 0 to 9 after the decimal point.
(ii) What are the most and the least frequently occurring digits?
To keep learning please visit our website www.byjus.com and download BYJU’S-The Learning App from Google Play Store.
Comments